学到了一个新的知识点或者新的协议,可以尝试解释给朋友或者同事听。比如在吃饭的时候,「嘿,你知道吗?TCP 三次握手的第三个包实际上是可以携带数据的!」然后他们会想这个问题,问你「要是有些 Server 不能处理带数据的第三个包怎么办?」这样,你就要重新思考你学的知识,看它是否考虑周全。教是最好的学习方法。如果没有朋友的话,可以考虑写一个博客(像我一样?呵呵)。
认识实际的网络,也可以从公司的网络结构开始。平时总结一下自己的问题,多阅读一些内部的文档。在内部 traceroute 跑一下,看看每一个 hop 都是什么。找时间请网络团队的同事吃饭,然后问他们你的问题。
举一反三
要学会提问。网络协议的目的一部分是传输数据,更重要的,它需要处理各种异常情况,保证即使出现各种意外,也能尽最大努力工作。所以,我们在学习的时候可以经常问题自己:如果这时候出现 xx 会怎么样呢?
问自己问题,然后思考,尝试给自己解答。在思考的过程中,会产生很多解决方案,大部分可能都是有问题的,然后找到其中的问题,推翻自己的方案。比如,网络为什么要分开三层和二层?这个世界上只有 IP 层,没有链路层行不行?或者只有链路层,不要 IP 层了行不行,整个世界都是一个「大二层」,会有什么问题?
说到最后,兴趣是最好的老师,对我来说,根据自己的知识和工具拨开迷雾,解决一个一个的问题,是再有意思不过的了。每个人会在人生的一个时间,发现这个世界不是公平的。但是在计算机的世界里,是很公平的,多花一点时间,多思考一些,就会多一分收获,它与天分无关。技术会过时,自己辛苦习得的技能也可能被 AI 轻而易举取代,但是曾经在学习和进步中体会到的乐趣是真实存在的,那些经验运用到新的技术中也多少是有所帮助的。祝愿读者在自己的领域体会到平静和乐趣。
有的时候 TCP 能够连通,有的时候无法连通。那么正常的 TCP SYN 包和异常的 TCP 包之间肯定是有什么字段是不一样的。当然,也有可能 SYN 包一模一样,问题出在了其他的网络设备上或者 TCP 的另一端。但是既然题目出给读者了,那么问题的根源肯定是隐藏在抓包文件里面。
通过对比来寻找答案
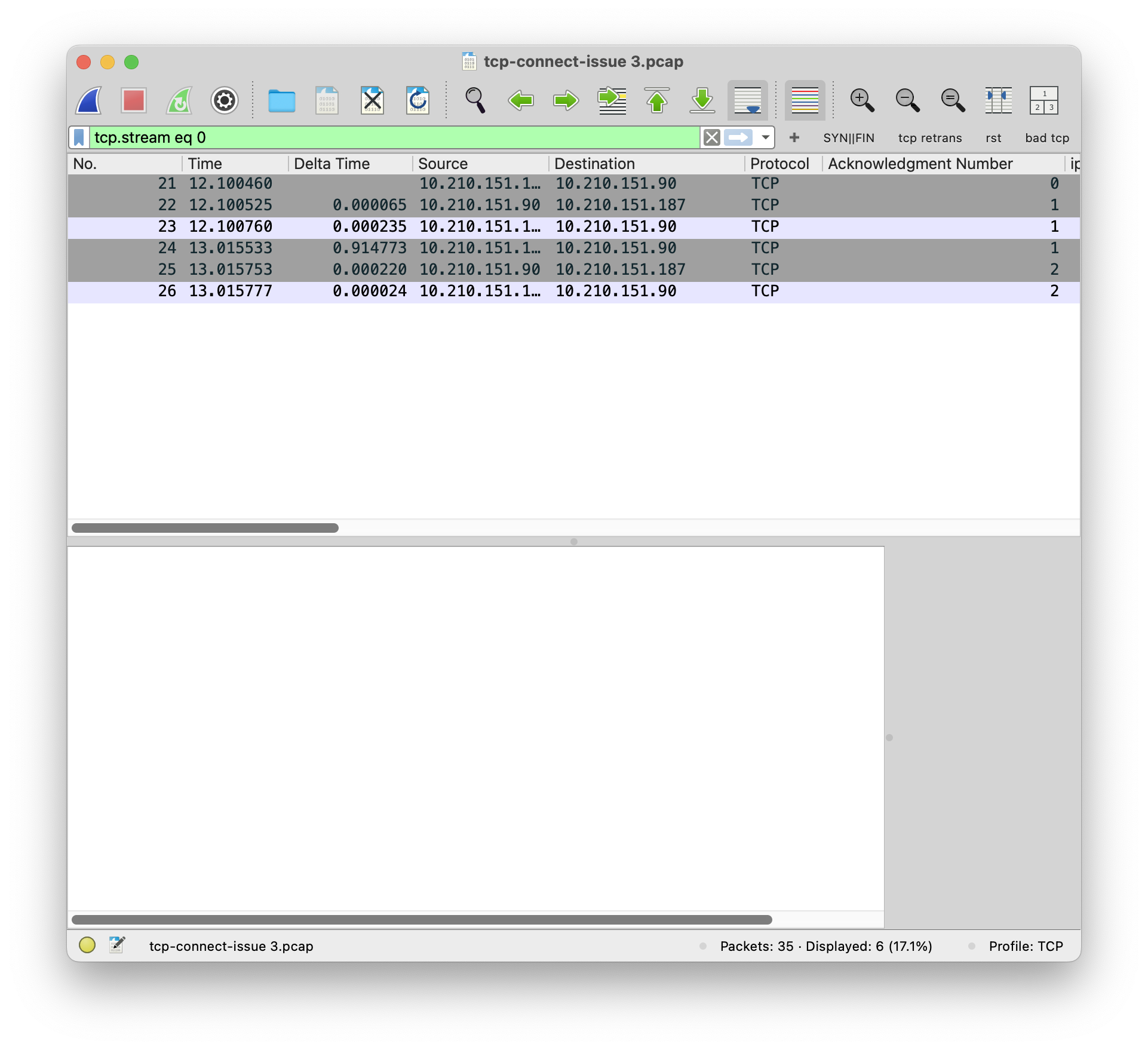
正常的 TCP 连接可以完成 TCP 的握手和挥手。
异常的 TCP 连接,发出去的 SYN 直接收到了 RST。
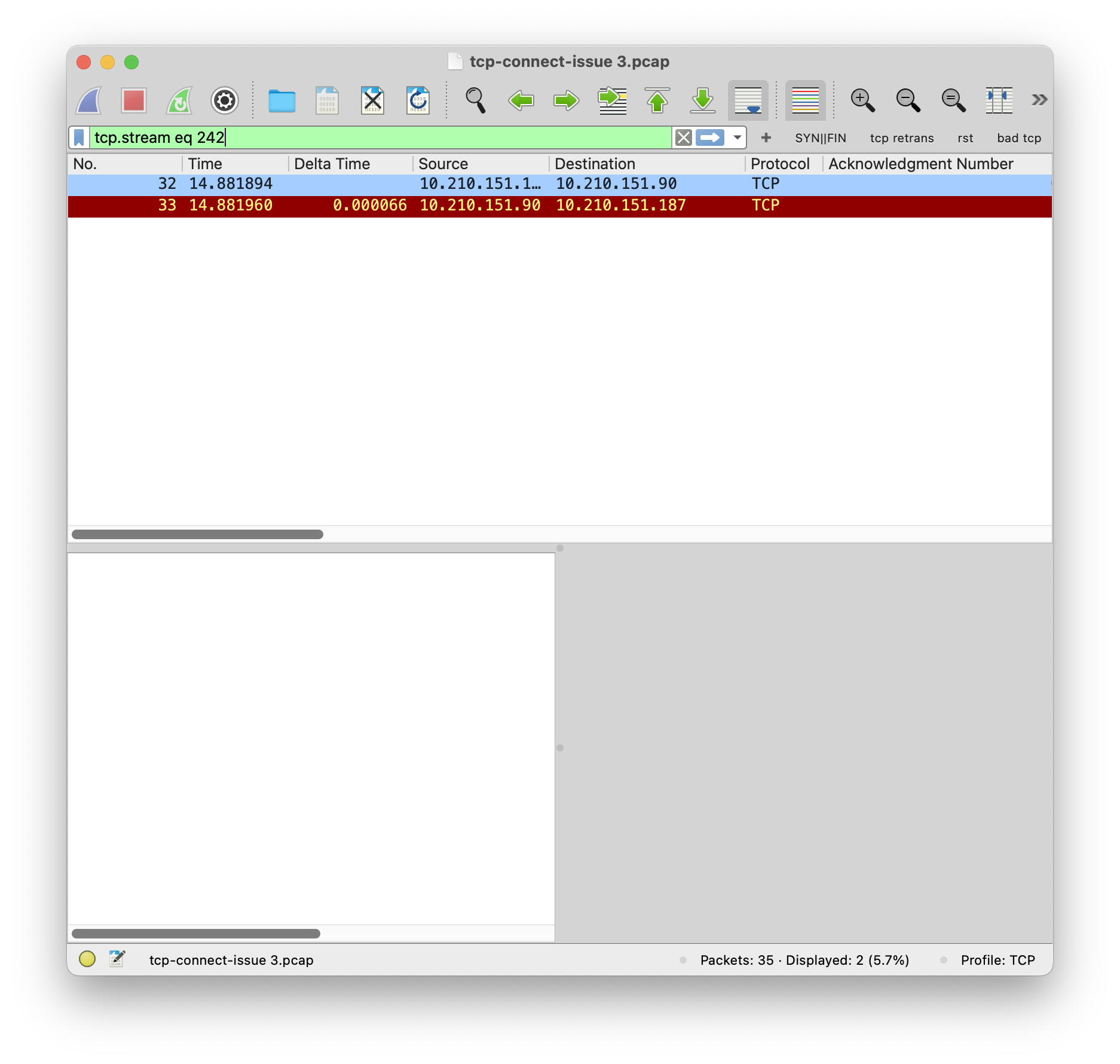
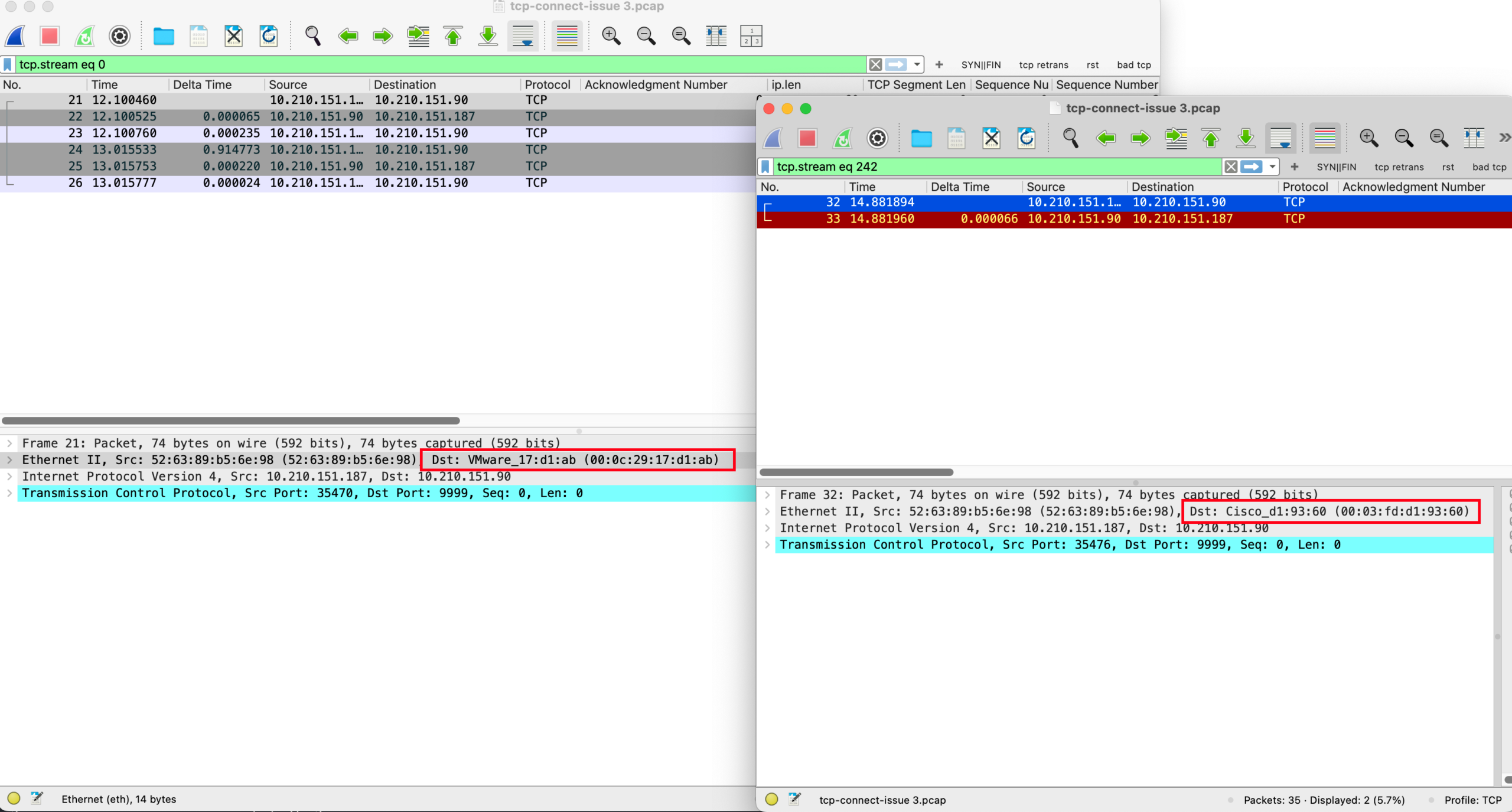
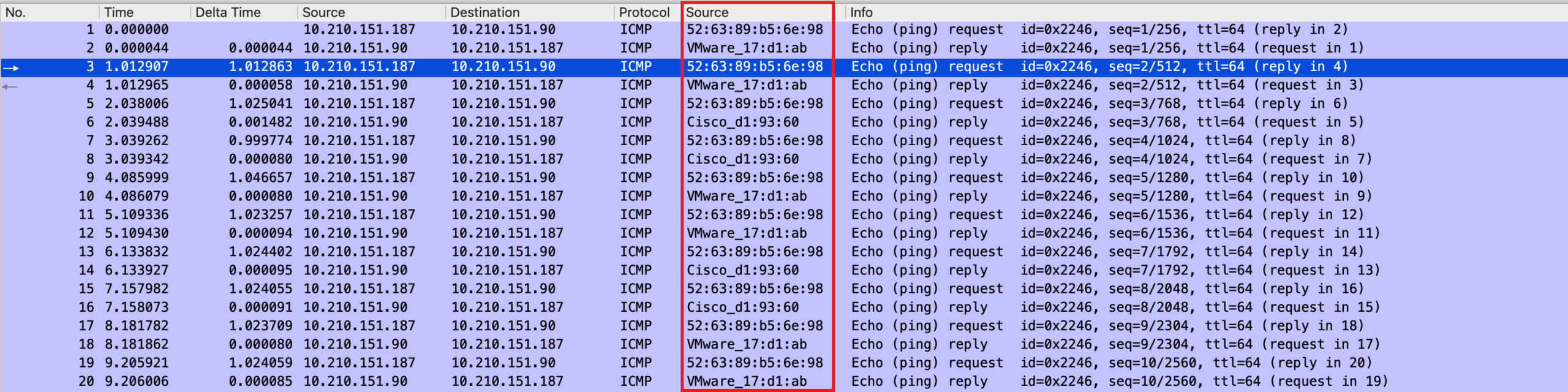
通过对比可以发现,两个 SYN 包的 Dst MAC 是不一样的。
通过推理得出答案
如果不通过对比的方法,顺藤摸瓜,可以用下面的思路。
首先,Src IP 和 Dst IP 分别是 10.210.151.187 和 10.210.151.90,很大概率是属于同一个 /24 子网的 IP,不过要想确认的话需要看下服务器的 IP 地址是如何配置的,子网掩码是不是 /24,这点我们从给出的信息无从得知。
假设确实是属于同一个子网,那么 TCP SYN 包不经过网关,直接发给目的地址,二层的 Dst MAC 地址应该是目的 IP 的 MAC 地址。
假设不属于同一个子网,那么 TCP SYN 包经过网关,TCP SYN 包的目的地址应该是路由器的 MAC 地址。
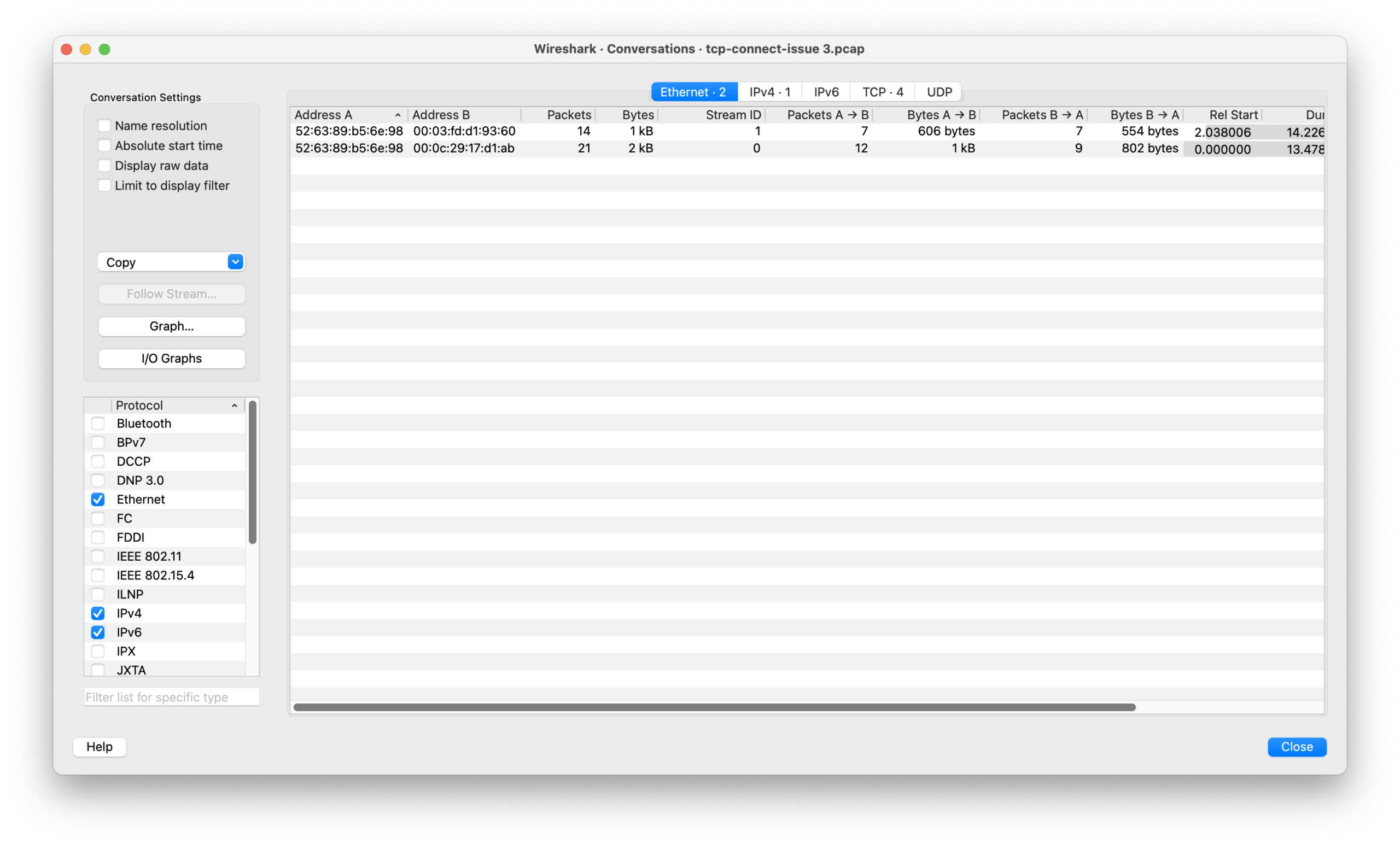
无论是那种情况,正常情况下发送给同一个 Dst IP 的目的 MAC 应该是唯一且稳定的。通过 Conversation 统计可以看出,通讯的 IP 对只有一对,但是 MAC 的确有 2 对,这是不对的。
Statistics > conversation
原因分析
造成这种现象的原因是,IP 分配重复了,在同一个子网内,同一个 IP 地址 10.210.151.90 被分配给了多个机器。
发送 TCP 包之前,需要知道对应的 Dst IP 地址的 Dst MAC 地址,怎么知道呢?Src 机器会在整个子网内广播 ARP 询问,持有这个 IP 的机器会回复 ARP。现在子网内有两个相同的机器是相同的 IP 地址。这两台机器的 IP 地址一样,MAC 地址不一样。如果我们现在 arping 10.210.151.90 ,会得到如下的回复:
可以把 Src MAC 地址添加到 Column 显示,就可以发现其实 ping 的回复来自不同的设备。
最后一个问题,为什么会有 IP 重复的问题呢?
DHCP 可以用来动态分配 IP 地址给设备,但是一般只用于客户端,比如办公网、家用网络中的终端设备,这些设备一般作为连接的发起方,不需要 listen 一个固定的 IP 地址,IP 地址的动态变化对它们影响不大。但是在 IDC 的网络中,每一个服务器的软件都需要固定的 IP 地址,一般不用 DHCP 来动态分配,而是用中心化的 IPAM 系统1追踪 IP 地址的分配情况。如果里面记录的地址不正确,比如,一个地址已经在使用中了,但是并没有在 IPAM 记录,就造成 IP 地址重复的问题。
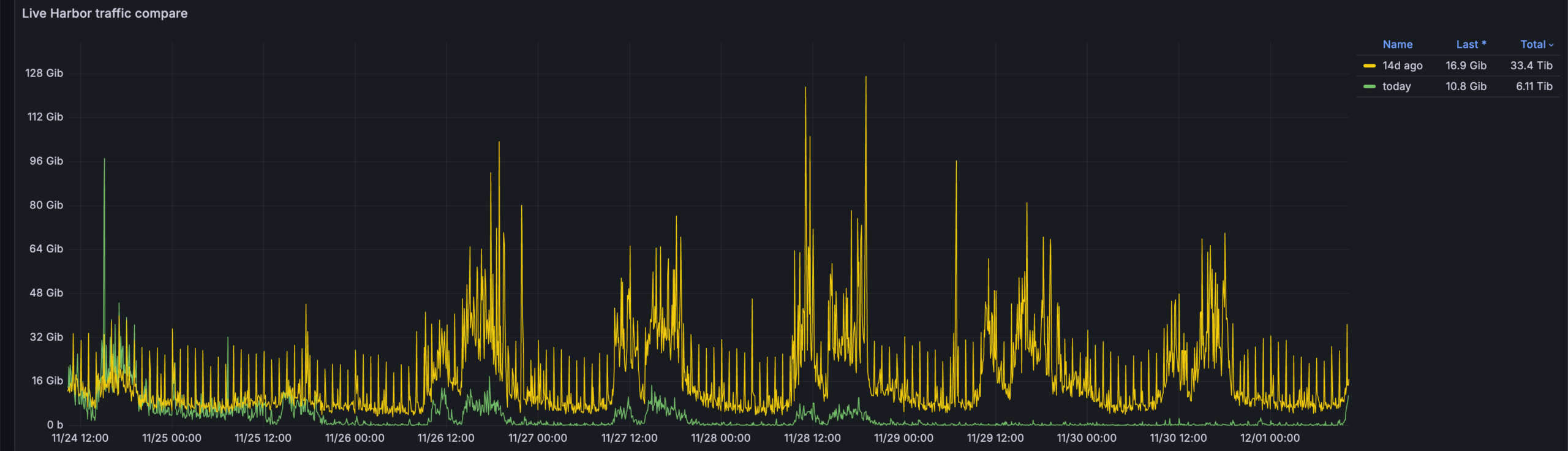
从这个监控可以看出,随着 Piccolo 的发布,Harbor 的流量骤降。而且每个小时的峰值流量也几乎没有了。
Pi 部署在每一个机器上,使用的资源也非常少,平均 CPU 用了一个 core 的不到 1%,可以忽略不计。平均内存用了 22M 左右,也可以忽略不计。
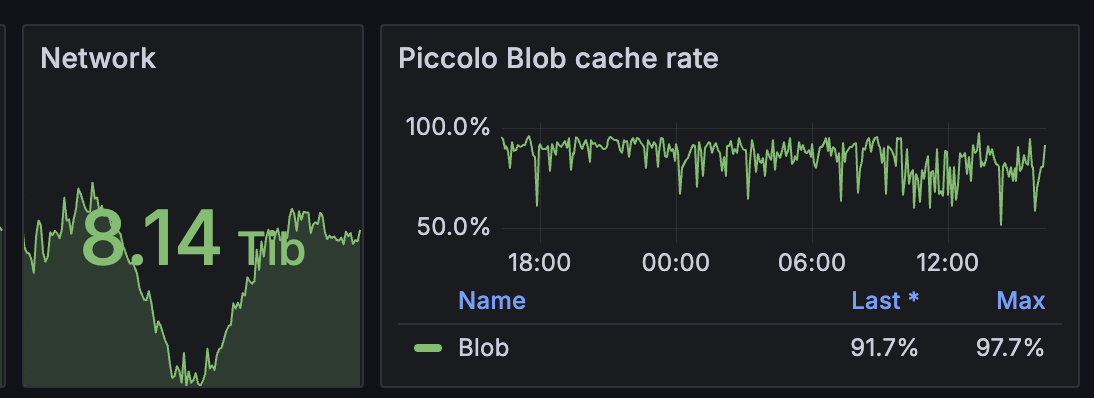
Piccolo 为集群提供了大约 8Tib 的下载带宽,没有消耗额外的资源,几乎是免费的 8Tib 带宽。
Piccolo server 方面,性能也很高,一台 8C8G 的 instance 足以支撑 5 万个 Pi (实际的物理机 worker 节点)。秘诀就是注重细节的性能优化。
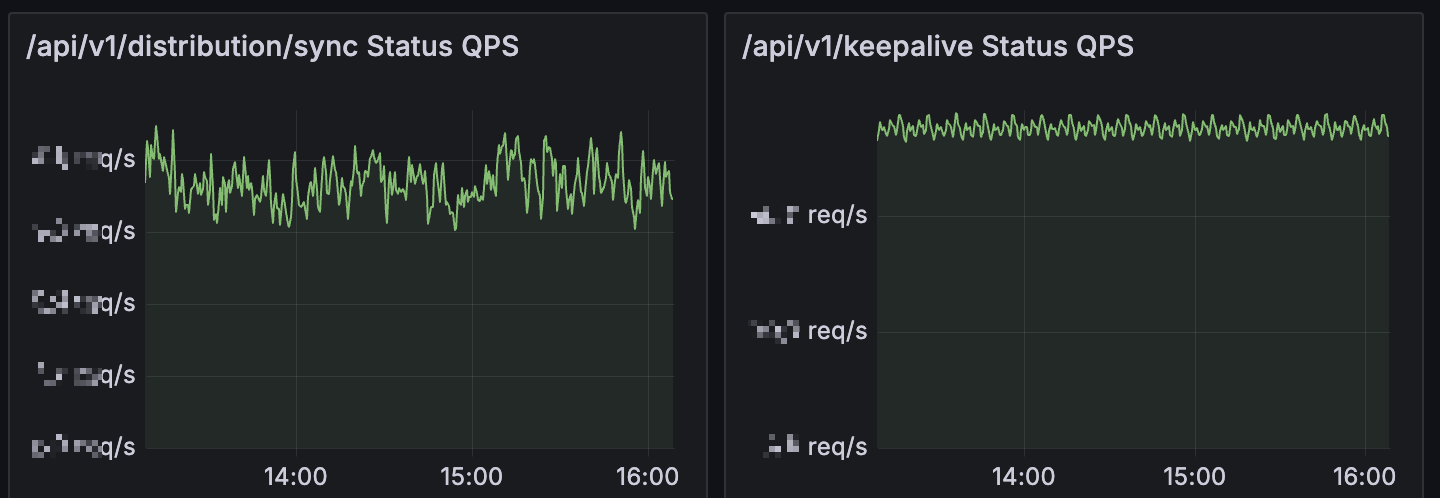
比如全量同步的资源消耗较大,一起部署的机器会定时发送 keeplive,通过对这些定时执行的 API 加随机偏移,可以保持这些 API 的频率几乎是均匀的,解决了资源的峰值问题。
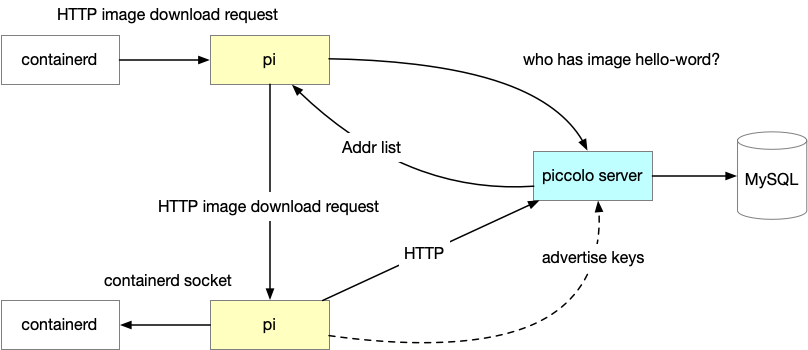
服务发现的核心,是用一张 MySQL 表,存储了 blob 和 IP 的对应关系。服务发现请求主要是通过这张表的查询完成的。Piccolo 支持把不同的 group(同一个 group 的 Pi 可以互相发现,不同的 group 的 Pi 不可以互相发现。其实这个功能也可以通过部署多个 Piccolo Server 来实现)放到不同的数据库中,加上索引优化(极致的索引优化,所有的查询都是 index-only 的),每一个库 2千万的数据,请求在 200 QPS,耗时在 10ms 以内,已经足够使用了。
Piccolo server 在服务发现接口返回的时候,会根据请求者的 IP 地址,把所有的资源拥有者的 IP,根据和请求者的 IP 相似度(距离)排序,返回。这样 Pi 在下载的时候,会从距离和它最近的邻居开始尝试,这样可以最大程度减少跨网络设备的带宽流量。
所有的 API 接口都有重试和指数时间退让,这样在大规模部署的时候,可以分散一些请求,不至于大家一起失败。
在高可用方面,由于 Piccolo server 是无状态的,所以部署多个实例即可。在预防未知的 bug 上,系统的每一个阶段都是可以降级的: